Machine Learning
Kembali bersama saya, Salman di blog ini. Pada Semester ke-5, saya mendapatkan mata kuliah "Machine Learning" salah satu mata kuliah yang paling penting untuk dipelajari karena ilmu yang dipelajari di dalamnya akan digunakan untuk menentukan sebuah metode yang sesuai seperti pengambilan, preprocessing, prediksi, klasifikasi, analisis, visualisasi pada suatu kumpulan data agar mendapatkan sebuah informasi yang dibutuhkan seorang peneliti. Sekilas, kita sudah mengenali kegunaan dari Machine Learning, tapi.. apasih Machine Learning itu?
Machine Learning adalah salah satu cabang dari perkembangan teknologi Kecerdasan Buatan atau Artificial Intelligence (AI) yang mampu mempelajari data yang ada dan melakukan tugas-tugas tertentu sesuai dengan apa yang ia pelajari. Machine Learning dikembangkan berdasarkan disiplin ilmu seperti statistika, matematika dan data mining sehingga mesin dapat belajar dengan menganalisis data tanpa perlu diprogram ulang atau diperintah.
Sejarah Machine Learning
Sekilas tentang sejarah Machine Learning pertama kali dikemukakan oleh beberapa ilmuwan matematika seperti Adrien Marie Legendre, Thomas Bayes dan Andrey Markov pada tahun 1920-an dengang mengemukakan dasar-dasar Machine Learning dan konsepnya. Sejak saat itu, Machine Learning mulai banyak yang mengembangkannya, salah satu contoh dari penerapan Machine Learning yang terkenal adalah Deep Blue yang dipelopori oleh perusahaan IBM (International Business Machine) pada tahun 1996.
Deep blue adalah Machine Learning yang dikembangkan agar dapat belajar dan bermain catur. Deep Blue telah diuji coba dengan bermain catur melawan juara catur profesional dan diketahui Deep Blue mampu mengevaluasi 200 juta peluang langkah per detik. Pertandingan antara Machine dan Manusia yang paling terkenal yaitu antara Deep Blue dan Garry Kasparov. Garry Kasparov menyerah terhadap Deep Blue setelah melakukan 19 langkah dalam pertandingan catur tersebut pada 10 Februari 1996.
Peran Machine Learning
Peran dari Machine Learning dapat kita temukan dalam kehidupan sehari-hari. Setiap dari kita pasti memiliki yang namanya sosial media, entah itu adalah facebook, instagram, whatsapp dan lain sebagainya. Pada sosial media seringkali kita disuguhkan sebuah saran atau iklan. Saran atau iklan yang disuguhkan tersebut merupakan pengolahan dari Machine Learning sesuai dengan kebiasaan kita di sosial media seperti konten yang sering kita lihat, kunjungi, sukai dan bagikan.
Selain itu, pada perangkat mobile saat ini terdapat fitur face unlock yaitu sebuah fitur keamanan menggunakan wajah pengguna yang datanya disimpan dan diolah melalui Machine Learning.
Teknik Belajar Machine Learning
Supervised Learning adalah teknik Machine Learning yang dapat menerima informasi yang sudah ada pada data dengan memberikan label tertentu. Diharapkan teknik ini dapat memberikan target terhadap output yang dilakukan dengan membandingkan pengalaman belajar di masa lalu.
Unsupervised Learning adalah teknik Machine Learning yang digunakan pada data yang tidak memiliki informasi yang bisa diterapkan secara langsung. Diharapkan teknik ini dapat membantu menemukan struktur atau pola tersembunyi pada data yang tidak memiliki label.
Beberapa Metode di Machine Learning untuk Analisis Data
Belajar tentang Machine Learning akan menemukan tiga istilah, yaitu Regresi (Regression), Klasifikasi (Classification) dan Klastering (Clustering). Ketiga istilah tersebut merupakan beberapa metode yang sangat populer di dunia Machine Learning dan Data Science. Lantas, apa itu Regresi, Klasifikasi dan Clustering?
Dalam menganalisis data, kita pasti mengharapkan sebuah informasi dari data yang sudah kita dapatkan. Dalam mendapatkan informasi tersebut, kita harus memilih metode yang sesuai pada data yang sudah terkumpul.
Regresi, Klasifikasi dan Clustering merupakan tiga metode yang sering digunakan untuk menganalisis sebuah kumpulan data. Sebenarnya masih banyak metode lainnya yang dapat digunakan, namun pada kali ini saya akan membahas tentang Regresi, Klasifikasi dan Clustering yang sedang saya pelajari di semester 5 ini.
Regression
Regresi adalah suatu teknik analisis untuk mengidentifikasi relasi atau hubungan di antara dua variabel atau lebih yang bertujuan untuk menemukan suatu fungsi yang memodelkan data dengan meminimalkan error atau selisih antara nilai prediksi dengan nilai sebenarnya. Regresi termasuk ke dalam supervised learning yang digunakan untuk memprediksi nilai kontinu.
Dalam Regresi terdapat dua jenis variabel, yaitu Dependant Variable dan Independent Variable. Dependent Variable adalah variabel yang akan diprediksi atau dipelajari, sedangkan Independent Variable adalah variabel yang menjelaskan atau menyebabkan nilai target di Dependent Variable.
Dependant Variable dinotasikan dengan "Y" sementara Independent Variable dinotasikan dengan "X". Di bawah ini merupakan contoh dari Dependant Variable dan Independent Variable.
Yang harus diperhatikan dalam kasus Regresi adalah nilai dari Independant Variable (X) harus berupa kontinu maupun kategori seperti pada contoh gambar di atas pada variable "body-style" yang memiliki nilai kategori "convertible", "hatchback", "sedan" dan "wagon" . Sementara pada Dependent Variable (Y) nilai dari variable nya harus berupa kontinu, bukan diskrit.
Terdapat dua cabang utama dari metode Regression , yaitu : Simple Regression dan Multiple Regression.
Simple Regression adalah ketika hanya satu variable independen yang digunakan untuk memprediksi dependen variabel, bisa berupa linear (Simple Linear Regression) maupun non-linear (Simple Non-linear Regression). Misalnya memprediksi harga ice cream hanya dengan berdasarkan cuaca saja seperti kategori panas atau dingin.
Multiple Regression adalah ketika ada lebih dari satu variabel independen yang digunakan untuk memprediksi variabel dependen. Misalnya memprediksi harga ice cream dengan beberapa variabel seperti suhu, kunjungan per-hari, strata ekonomi pengunjung dan lain sebagainya.
Penerapan Regresi di Machine Learning menggunakan Jupyter
Pertama kita akan melakukan instruksi untuk import library numpy, pandas, matplotlib dan sklearn
Library numpy digunakan untuk menghitung data, library pandas digunakan untuk visualisasi data, library pyplot dari master library matplotlib digunakan untuk plot visualisasi data.
Menggunakan fungsi pd.read_csv() untuk memanggil kumpulan data yang tersimpan di dalam file "latihanregresi.csv". Fungsi tersebut disimpan di dalam variabel "dataset".
Menampilkan seluruh kumpulan data dari file "latihanregresi.csv" dengan cara memanggil variabel "dataset".
Script di atas adalah sebuah perintah untuk menampilkan data dengan sebuah visualisasi plot DataFrame. Untuk menampilkan sebuah tampilan Data Frame seperti di atas membutuhkan library pyplot dari master library matplotlib.
Setelah itu, untuk membuat sebuah pemetaan pada Data Frame.. kita membutuhkan fungsi plot scatter untuk menunjukkan visualisasi data dari variabel yang terdapat pada file "latihanregresi.csv". Karena pada file "latihanregresi.csv" hanya terdapat variabel "x" dan "y", maka untuk menampilkan visualisasi data menggunakan syntax "plt.scatter(data.x, data.y)".
Sekarang kita memasuki untuk memulai perhitungan data menggunakan numpy.
variabel x menyimpan sebuah fungsi np.array() yang di dalamnya terdapat parameter data.x yang berarti menyimpan seluruh kumpulan data pada variabel x di file "latihanregresi.csv". Selanjutnya terdapat parameter yang kedua yaitu "dtype = np.float32" yang berarti seluruh data di variabel x bertipe data float.
Sama seperti pada variabel x, namun pada variabel y hanya menyimpan seluruh kumpulan data pada variabel y menggunakan fungsi np.array().
variabel x_train = menyimpan sebuah fungsi dari x.reshape(-1,1) yang berarti merubah sebuah tampilan data menjadi sebuah kolom (-1,1) atau menurun ke bawah.
Memanggil variabel "x_train" untuk melihat tampilan dari variabel "x" setelah dilakukan modifikasi data dengan fungsi "x.reshape()".
Sama seperti pada variabel "x_train", namun pada variabel "y_train" hanya menyimpan kumpulan data pada variabel "y" dan tidak dilakukan sebuah modifikasi data dengan fungsi ".reshape()".
Jika variabel "y_train" langsung dipanggil, maka tampilannya akan berbeda dengan variabel "x_train" yang sudah dimodifikasi datanya.
Sekarang kita hanya mengimport library "LinearRegression" dari master library sklearn.linear_model yang akan digunakan untuk melakukan analisis data menggunakan Regresi Linear.
Fungsi "LinearRegression()" disimpan di dalam variabel "model".
fungsi "fit()" yang diterapkan pada variabel "model" --> model.fit() yang berarti melatih model pada variabel "model" untuk memprediksi hasil model. Untuk training data pada variabel "model" dibutuhkan untuk training data dan testing data dengan proporsi tertentu.
Pada syntax di atas bertujuan untuk mengetahui nilai dari suatu slope atau nilai kemiringan dan nilai dari intercept atau perpotongan antara variabel x dan y sebagai predict dan testing
Decision Tree
Algoritma decision tree adalah algoritma machine leraning yang menggunakan seperangkat aturan untuk membuat keputusan dengan struktur seperti pohon yang memodelkan kemungkinan hasil, biaya sumber daya, utilitas dan kemungkinan konsekuensi atau risiko.
Konsep dari algoritma decision tree adalah dengan cara menyajikan algoritma dengan pernyataan bersyarat yang meliputi cabang untuk mewakili langkah-langkah pengambilan keputusan yang dapat mengarah pada hasil yang menguntungkan.
Setiap percabangan dari algoritma decision tree mewakili untuk setiap atribut, sedangkan jalur dari daun ke akar mewakili aturan untuk klarifikasi. Hal tersebut yang menjadi alasan algoritma ini disebut sebagai algoritma decision tree karena output dapat menyerupai sebuah pohon.
Kelebihan dan Kekurangan dari Algoritma Decision Tree :
Kelebihan :
- Mudah dibaca dan ditafsirkan tanpa perlu pengetahuan statistik
- Mudah disiapkan tanpa harus menghitung dengan perhitungan yang rumit
- Proses Data Cleaning cenderung lebih sedikit, kasus nilai yang hilang dan outlier kurang signifikan pada data decision tree
Kekurangan :
- Sifat tidak stabil sehingga menjadi salah satu keterbatasan dari algoritma decision tree ketika terdapat perubahan kecil pada data dapat menghasilkan perubahan besar dalam struktur pohon keputusan
- Kurang efektif dalam memprediksi hasil dari variabel kontinu
Penerapan Algoritma Decision Tree di Machine Learning menggunakan Jupyter
Pada kasus ini, kita akan melakukan prediksi cuaca untuk menentukan kondisi seperti apa yang sesuai agar suatu pertandingan tennis dapat dilaksanakan menggunakan Algoritma Decision Tree. Dataset yang akan digunakan adalah "tennis.csv" dengan parameter "outlook, temp, humidity, windy dan play"
Parameter yang dipengaruhi oleh parameter lainnya adalah paramater "play" sebagai hasil dari proses prediksi oleh mesin. Dataset dapat diunduh pada link di bawah ini :
langkah pertama adalah melakukan import library master pandas yang akan digunakan untuk visualisasi data pada data yang akan digunakan yaitu "tennis.csv" dan disimpan di dalam variabel "dataset"
Untuk menampilkan seluruh dataset cukup memanggil variabel "dataset"
variabel x menyimpan dataset pada parameter temp
variabel y menyimpan dataset pada parameter play sebagai data yang akan dipengaruhi oleh dataset pada parameter temp.
Kali ini kita akan melakukan input dataset secara otomatis menggunakan library iris dari master library sklearn.metrics
mengisi dataset menggunakan function "load_iris()" yang disimpan di dalam variabel "iris" kemudian memanggil variabel iris untuk melihat dari data yang sudah diisi (load)
Melakukan pembagian (split) data training dan data testing menggunakan library train_test_split dari master library sklearn.model selection
Nilai data yang diujikan sebesar 0.3 atau sebesar 30% dari data asli dengan pernyataan acaknya adalah 0
Sekarang kita akan melakukan prediksi menggunakan algoritma Decision Tree dengan cara mengimpor library DecisionTreeClassififer dari master library sklearn.tree
Fungsi utama DecisionTreeClassifier() disimpan ke dalam variabel "model"
variabel model melakukan fit yang di dalamnya terdapat parameter x dan yang sebelumnya sudah diujikan.
mengimport library matplotlib.pyplot sebagai plt yang nantinya akan digunakan untuk plot atau visualisasi diagram dari hasil proses prediksi menggunakan algoritma decision tree.
Berikut adalah hasil dari prediksi menggunakan decison tree
Naive Bayes
Algoritma Naive Bayes disebut "naif" karena membuat asumsi bahwa kemunculan fitur tertentu tidak tergantung pada kemunculan fitur lainnya.
Misalnya jika pada suatu kasus untuk mendeteksi buah berdasarkan warna, bentuk dan rasanya, maka buah berwarna oranye, bulat dan tajam kemungkinan besar adalah jeruk. Bahkan jika ciri-ciri bergantung satu sama lain atau pada keberadaan ciri-ciri lain, semua sifat ini secara individual berkontribusi pada kemungkinan bahwa buah ini adalah jeruk dan itulah sebabnya buah ini dikenal sebagai naif.
Kelebihan dan kekurangan dari Naive Bayes :
Kelebihan :
- Klasifikasinya mudah diimplementasikan dan cepat
- Membutuhkan lebih sedikit data pelatihan (training)
- Dapat membuat prediksi probabilistik dan dapat menangani kontinu beserta data diskrit
- Algoritma klasifikasi Naive Bayes dapat digunakan untuk biner maupun multi kelas masalah klasifikasi keduanya.
Kelemahan :
- Klasifikasi Naive Bayes adalah frekuensi 'nol' yang berarti bahwa jika variabel kategori memiliki kategori tetapi tidak diamati dalam data pelathian set, maka model Naive Bayes akan menetapkan probabilitas nol untuk itu dan tidak akn dapat untuk membuat prediksi
Penerapan Algoritma Naive Bayes di Machine Learning menggunakan Jupyter
Algoritma K-Nearest Neighbour (KNN)
Algoritma K-Nearest Neighbour (KNN) digunakan untuk menyelesaikan masalah klasifikasi dan regresi. Algoritma ini termasuk dalam jenis supervised learning. Algoritma KNN bersifat non parametric dan lazy learning.
Metode yang bersifat non-parametric memiliki arti bahwa metode tersebut tidak dapat membuat asumsi apapun tentang distribusi apa yang mendasarinya. Dengan kata lain, tidak ada jumlah parameter atau estimasi parameter yang tetap dalam model, terlepas data tersebut berukuran kecil ataupun besar.
Algoritma KNN menggunakan sejumlah parameter yang fleksibel dan jumlah parameter seringkali bertambah seiring data yang semakin banyak. Algoritma non-parametric secara komputasi lebih lambat, tetapi membuat lebih sedikit asumsi tentang data.
Algoritma KNN juga bersifat lazy learning yang berarti tidak menggunakan titik data training untuk membuat model. Singkatnya pada algoritma KNN tidak ada fase training, kalaupun ada sangat minim.
Semua data training digunakan pada tahap testing. Hal ini membuat proses training menjadi lebih cepat dan tahap testing lebih lambat dan cendeurng mahal atau membutuhkan banyak cost dari sisi waktu dan memori.
Dalam kasus terburuk, KNN membutuhkan lebih banyak waktu untuk memindai semua titik data. Proses ini juga akan membutuhkan lebih banyak memori untuk menyimpan data training.
Penerapan Algoritma K-Nearest Neighbour (KNN) di Machine Learning menggunakan Jupyter
Support Vector Machine (SVM) Algorithm
Support Vector Machine (SVM) merupakan salah satu algoritma machine learning dengan pendekatan berbasis supervised learning yang dapat digunakan untuk masalah klasifikasi dan regesi. Selain itu, SVM dapat digunakan untuk menganalisis data dan mengurutkannya ke dalam salah satu dari dua kategori.
SVM bekerja untuk mencari hyperplane atau fungsi pemisah (Decision Boundry) terbaik untuk memisahkan dua buah kelas atau lebih pada ruang input. Hyperplane dapat berupa line atau garis pada dua dimensi dan dapat berupa flat plane pada multiple plane.
2 Jenis dari Algoritma SVM yaitu SVM Linear dan SVM Non-linear :
SVM Linear digunakan untuk data yang dapat dipisahkan secara linear, yang berarti jika sebuah dataset dapat diklasifikasi menjadi dua kelas dengan menggunakan sebuah garis lurus tunggal, maka data tersebut disebut sebagai data yang dapat dipisahkan secara linear dan classifier yang digunakan disebut sebagai Linear SVM Classifier.
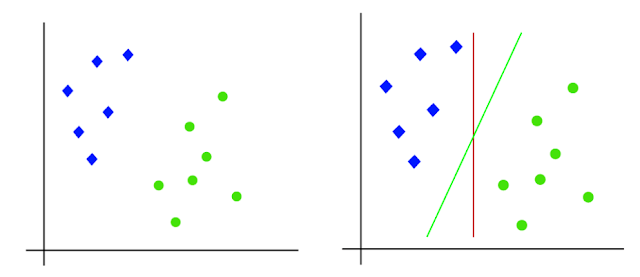 |
| Dataset yang sudah diklasifikasikan kemudian diproses menjadi SVM Linear |
SVM Non-linear digunakan untuk data yang dapat dipisahkan secara non-linear, yang berarti jika sebuah dataset tidak dapat diklasifikasi menggunakan garis lurus, maka data tersebut disebut data non-linear dan classifer yang digunakan disebut sebagai non-linear SVM Classifier
Kelebihan dan kekurangan dari Algoritma SVM
Kelebihan :
- Efektif untuk kasus di mana jumlah dimensi lebih besar dari jumlah sampel
- Hemat memori, karena menggunakan training point dari fungsi keputusan
- Bekerja relatif baik ketika ada margin pemisahan yang jelas antar kelas
Kekurangan :
- Algoritma SVM tidak cocok untuk dataset dalam jumlah yang besar karena membutuhkan waktu training yang lama.
- SVM tidak bekerja dengan baik ketika dataset memiliki lebih banyak noise misalkan kelas target terjadi tumpang tindih.
- Jika jumlah fitur untuk setiap titik data melebihi jumlah sampel data training, SVM akan memiliki performa yang kurang baik.
- Karena SVM classifier bekerja dengan meletakkan titik data di atas dan di bawah hyperplane, tidak ada kejelasan probabilistik untuk klasifikasi tersebut. Hal ini dapat menyebabkan beban komputasi yang tinggi.































Tidak ada komentar:
Posting Komentar